やはり「C/C++ は難しい」という声をよく聞く。
実際、最近、twitter でこんなやりとりがあった。
ワイも極めるレベルまではいってないが、まあ困らない程度には使える。
古今東西の C で書かれたライブラリを使うために悪戦苦闘しているうちに何となく覚えてしまった。
C/C++ の習得を難しくしている原因の一つは、ポインタだろう。
ポインタの基本
twitter でも書いたが、ポインタの簡単なサンプルを上げておくとこんな感じか。
//test.c
#include <stdio.h>
int main(){
//int *a;
int* a;
int b=100;
a = &b;
printf("%d", *a);
}
これをコンパイルする。素直にコンパイルするなら、こんな感じか。
gcc -o test test.c
これで test という実行可能なファイルができる。
実行させると、もちろん
100
と表示される。
わざわざ
int *a
も書いておいたのは、こう書いても結果は変わらないから。
ただ、こう書くと初学者の理解はがこんと悪くなるという印象を持っている。
なんで、ここでわからなくなるかといえば、おそらく、宣言時の *a と最後の printf で( a で差し示されている)実際の数値を表示させる *a を混同してしまうからだと思う。
ポインタ変数といえども変数には変わりなく、宣言が必要だ。もちろん、型も必要。
上の場合は、int 型のポインタ変数 a を宣言したいのだから、int* と書いた方が(少なくとも初学者にとっては)混乱は減ると思う。
あくまで変数としては a なのだから。
通常の変数と違うのは、ここにアドレスが格納されるという特殊性だろう。
a 自体はアドレスなのだから、その(アドレスで示されている)実体を知りたければ何らかの操作が必要で、シンプルに * をつける。
* は宣言時にも使われるので、両者を混同してしまうのだろう。
次の難所 -文字列と配列-
ポインタの概念が分かってもそれだけでは使えないと思う。
これはおそらく C の配列や文字列の扱いのせいでしょう。
取り扱いというか約束事ね。
配列
上のようなプリミティブな数値型の場合、ポインタを使いたければ * を使えばよかったが、配列も同じようにするとうまくいかない。
つまり
int[] *a;
という表現はしない。
というかする必要がない。
というのは、C では、配列 array[] などと書いた場合、array つまり配列変数名自体はその先頭要素へのポインタになっているからだ。
サンプルコードを示すと以下のようになる。
#include <stdio.h>
int main()
{
//int[] *p;
int array[]={1,2};
printf("%d",*array);
return(0);
}
結果は 1 。
int[] *p という宣言は、エラーになる。
ところで、こういう書き方は、近年の配列に要素数が簡単に追加できたり型推論してくれたりする言語に慣れた人からすると、奇異に映るようだ。
奇異というか不安に近い感情だろうか。
array に要素を追加したい場合、どうするんですか?と。
安心して欲しい。C では、原則、要素数の追加はできない。
(C での可変長配列に関してはここらあたりの記事参照)
なお、この場合、配列 array の要素数を知りたければ、以下のようななんとも面倒くさい書き方になる。
(こちらのオンライン C コンパイラーサイトを使用)
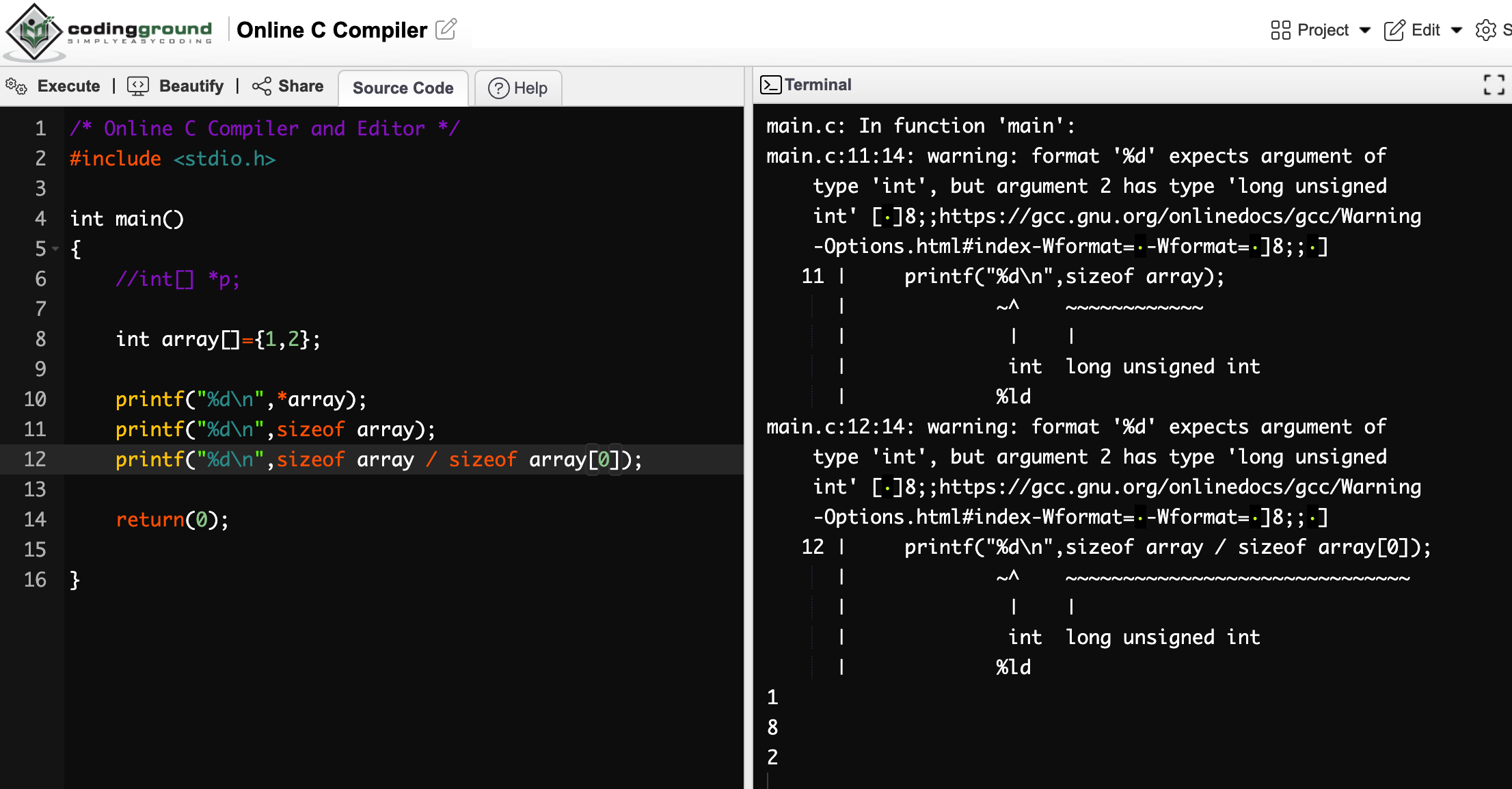
array 自体のメモリサイズを sizeof で求めて、それを要素のバイト数で割って、ようやく要素数を知ることができる。
このコードにしても unsigned 絡みでワーニング出てますけどね。
ついでで言っておくと C/C++ ではファイルサイズを調べるときも(直接これを調べるような関数のようなものは提供されていないので)同様に若干手間のかかるアプローチを取る必要がある。
このツィなど参照。
大きさを調べるときには注意が必要
なお、(初学者は絶対混乱すると思うが)array[] という書き方と *array という書き方は C コード内で厳密にはまったく同じ挙動をするわけではない。
よく知られた例としては、sizeof(*array) とするとポインタの大きさを返すのみで、array 自体の大きさを返しているわけではない。
バグの原因となる。
ちょっと実用的なサンプル -バイナリファイルを 2byte 毎に読み込む-
ここら辺の仕様はややこしいところだが、実務的には便利なときがある。
あるバイナリファイルがあった時、これをバイト配列ではなく、2byte や 4byte の数値配列として読み込みたいということがよくある。
C++ になってしまうが、以下のようなコードはよくお目にかかる。
const char* fname="(PathTo)/sample.raw";
std::ifstream ifs(fname, std::ios::binary);
ifs.seekg(0,std::ios::end);
uint64_t size = ifs.tellg();
ifs.seekg(0);
uint16_t *data16 = new uint16_t[size/2];
ifs.read((char*)data16,size);
このコードのキモは
ifs.read((char*)data16,size)
だ。
ifstream::read() は、仕様的にはバイト配列しか読み込めないが、2byte 配列 data16 のポインタをバイト配列のポインタでキャストすることで 2byte の配列として読み込んでくれる。
いったん、バイト配列として読み込んだ後、2byte の配列にマッピングし直して・・・という複雑な処理は必要ない。
これをやるためには、ファイル自体の大きさ(バイト数)を予め知っておく必要があるが、その処理は前段で行なっている。ファイルの大きさ一つとってもこういう書き方をする。
なお、このコードの意味を理解したときはいたく感動した。
ポインタが使われている例としてよく知られたものだが、もう一つ例示しておくと main(argc, *argv[]) の意味もわかってみるとなんということはない。
こちらの記事あたり参照。

配列を舐めてはいけない
ところで、ポインタの話をすると、そこだけに注力してしまい、その他の知識が疎かになりやすい。
ポインタと配列の関連が深いのは上でも述べたが、実用的なプログラミングでは両方の知識を絡ませないとにっちもさっちもいかない。
C の配列で知っておかなければいけない知識は、
配列は初期化しないと使えない
という(ポインタに比べるとあまり注意を払われないんだが)超重要仕様。意外に理解してない人が多い。
初期化には、最初から全てを代入するとか初期化子を使う方法とかいくつかやり方があるんだが、最近のワイの好みは memset などを使って、根こそぎメモリ領域を確保しておく方法。
uint16_t testarray[100];
memset(testarray, 0, sizeof(uint16_t)*100);
あるいは(ややこしいが、こちらの方が実用的)、
uint16_t *testarray = (uint16_t *)calloc(100, sizeof(uint16_t));
// any code you want
free(testarray);
これで全ての要素に 0 が入るので、この初期化以降は testarray[50] だのに好きな値を代入できる。
もちろん、C の配列の使い方(可変長が許されない&初期化する必要がある)は、不便を感じることが多く、例えば MacOS/iOS のアプリを作成する際には、配列のみで攻めていく、ということはないと思う。
なお、最近、実感しているのは、NSData の優秀性。
長さが不定な重要データは NSData 型で管理し、具体的な処理は C ライブラリに任せるとかやると混乱は減る。
「ポインタ」は重要だが、ポインタだけじゃダメって話です。
参考:『配列を自由自在に作る』など。
C で配列が使いにくい→ malloc などで対応、という流れが簡潔に説明されている。
malloc + memset = calloc という感覚なのだが、具体例が出たときにでも追記したい。
こちらの記事もいい。
最初はピンとこないかもしれないが
配列[変数]
となっている配列を扱いたいときにここら辺の知識があやふやだと、うまく扱えない。
逆に「C 使えるようになってきたかな?」と実感できるのはここら辺の知識が身についてきたとき。
Xcode プロジェクトで C/C++ でファイル入出力を扱うとき
アップルの話が出てきたので、ついでに。。。
最近、プライベートでは Mac 使う場合が多いが、これ(↓)知ってないとハマるかも。
デフォでは、ファイルアクセスに制限がある
BAD_ACCESS 関係のエラーが出たら、設定を見直しておきましょう。
参考
『C 言語における 16 進表記文字列⇄バイナリ列変換』この配列操作はしばしば話題になるが、これで決定かな。
magicarray を使ったロジックが美しい。