
以前に Mac 環境で C を使う場合、バイナリバイト列などのデータは NSData に任せた方がいいということは述べた。
いうまでもなく、C のデータの取り扱いの煩雑さは負担と考えているからだ。
そうはいっても、 既に(Objective ではない素の)C で各種データの定義が完了しているような場合、そういうわけにもいかない。例えば C で書かれた汎用ライブラリの機能に大きく依存しているようなプロジェクトではどうしてもどうなってしまう。
ここら辺、どの部分を NSData (というか cocoa の各種フレームワーク)に割り振り、どの部分を C で押し通すのかは、センスの出るところだと思う。
ところで、C 言語に関しては、巷の C 談義のようなものだけではうまくいかないと感じている。
ポインタの話は C を語る上で重要だが、ポインタだけ知っていても実用的なコードが書けるとは思えない。
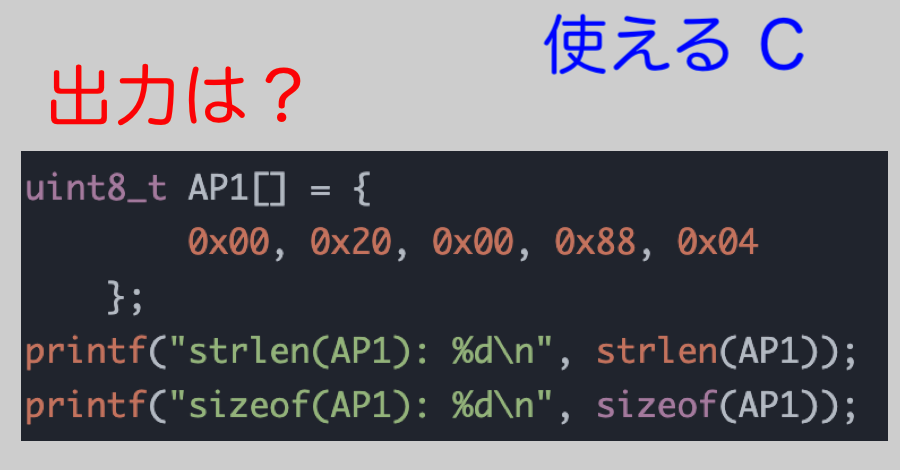
ところで、この前、さるプログラムに不具合が出て、原因を調べていて気がついたのだが、以下のコードを実行した場合、結果はどうなると思います?
uint8_t AP1[] = {
0x00, 0x20, 0x00, 0x88, 0x04
};
printf("strlen(AP1): %d\n", strlen(AP1));
printf("sizeof(AP1): %d\n", sizeof(AP1));この部分だけを取り出すとわかりやすいと思うが、結果は
strlen(AP1): 0
sizeof(AP1): 5となる。
「終端文字 0x00 が先頭にあるのだから、文字列の長さを求める strlen では 0。使われているメモリのバイト数を求める sizeof では 5。当たり前じゃないか」と言われるかもしれないが、実際の(不具合のあった)コードはこんなにわかりやすくはない。
具体的には AP1 の末尾にバイト列を追加してバイト列を生成するためのメモリ確保の段階で
malloc(strlen(AP1) + strlen(hoge))とやっていたんだな。
実は、これらコードを含むプログラムは USB を制御するコマンドで AP1[5] もそのコマンドの一つだった。
実際にデバイスを制御するわけだから、コマンドといえどもバイナリデータであってもおかしくはないのだが、そこら辺の事情をわからず「コマンド」と言われれば文字列を連想するのが普通ではなかろうか。
で、文字列と思いこんでこのような実装になってしまったと。
この手の不具合が発見しにくいのは、0 を含まない「コマンド」の場合は正しく動作してしまうからだ。
なお、バイト列とバイト列を結合させたい場合には
uint8_t cmd[sizeof(AP1)+sizeof(hoge)];
memcpy(cmd, AP1, sizeof(AP1));
memcpy(cmd+sizeof(AP1), hoge, sizeof(hoge));出力させる時は
for (int i = 0; i < sizeof(cmd); i++) {
printf("%02x", cmd[i]);
}と書くとわかりやすいでしょうか。