今までよく分かってなかったプロセス・スレッド・同期・非同期云々を今のうちにまとめておこうと思い、ネット上を散策。
とりあえず、ここから始まる書き物を読んでいたのだが、読み進めるうちにちょっとイライラしてきた。
なんでこの人は、Xinu というそれほどメジャーとは言えないような環境でテストしているんだろうか?
今、現在、この仕事の評価が即できるほどの力量を持ち合わせていないので、なんとも言えないのだが、現在、使いやすい環境を一つ選んでサンプル載せた方が利便性という意味では良いと思う。
Linux, MacOS, Windows なんでもいいでしょ。
その一方で、ネットには(まとまっていないものの)「おお!」と呻きたくなるような有用なサンプルコードが落ちている。
文句ばかり言っても始まらないので、それらを収集して、暫定的なコメントをつけていく。
fork() とプロセス
まずは、以下のサンプルコードを実行してみよう。
fork.c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
pid_t pid;
pid = fork();
printf("PID=%d\n", pid);
exit(0);
}
実行形式のファイルを得るのは、Linux or MacOS なら、上のコードをテキストファイルに書き込んで
gcc fork.c -o fork
でいい。それだけ。
実行すると
% ./fork
PID=80644
PID=0
という結果が得られる。
この PID というのは 「システム管理者が端末から ps コマンド叩いて、何やらやっている PID のこと?」と思うかもしれないが、その通り。
次に以下のコードも同様に実行。
fork2.c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
pid_t pid;
pid = fork();
printf("PID=%d %d\n", pid, getpid());
getchar();
exit(0);
}
同様に実行すると getchar() でこのプログラムは入力待ちとなり一時停止する。
この状態で他の端末から ps してみよう。
% ps
PID TTY TIME CMD
48613 ttys000 0:00.17 -zsh
31547 ttys001 0:00.90 /bin/zsh -il
85863 ttys001 0:00.02 ./fork2
85865 ttys001 0:00.00 ./fork2
予想通り、PID はあの PID だった。
なお、「通常子プロセスは exec コマンドと組み合わせて他のプログラムを起動するときに使われる」と説明されているが、具体的なコードがない。
このわかりやすい例が StackOverFlow にあったので、あげておく。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
int main (void) {
pid_t processId;
if ((processId = fork()) == 0) {
char app[] = "/bin/echo";
char * const argv[] = { app, "success", NULL };
if (execv(app, argv) < 0) {
perror("execv error");
}
} else if (processId < 0) {
perror("fork error");
} else {
return EXIT_SUCCESS;
}
return EXIT_FAILURE;
}
ところで、このコードは参考(下参照)から拾ってきたが、この著者の説明は明快で、こちらの記事でプロセスとスレッドについて実に簡潔に説明している。
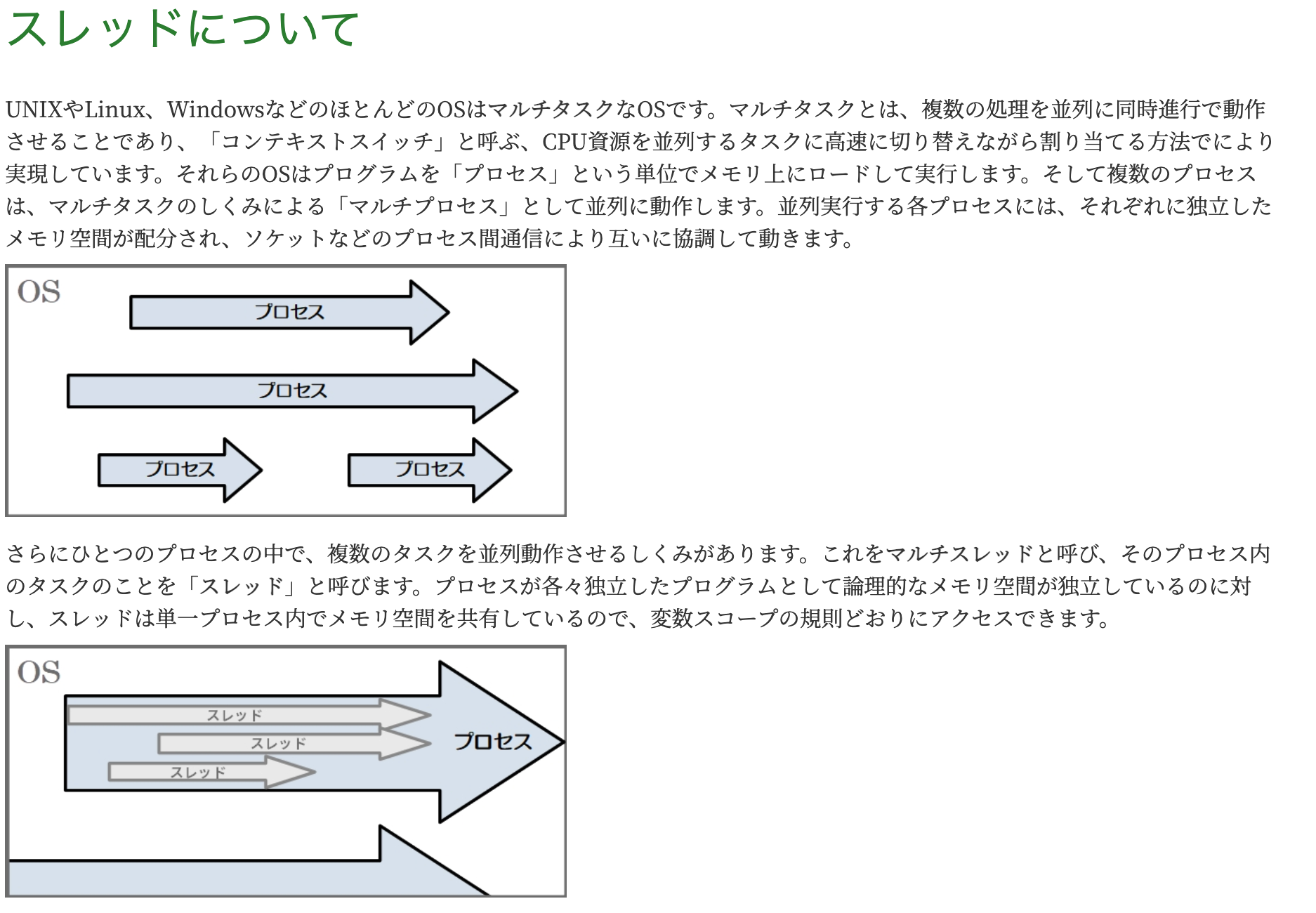
普通はこういう理解だと思う。
最近このブログでは NativeMessaging を取り上げたが、NativeMessaging は通常「プロセス間通信」と呼ばれていると思う。
一つのプロセスは chrome 拡張の JavaScript プログラム、もう一つのプロセスは host のネイティブアプリ。
なんで大学教授のやつがイライラしたかと言えば、通常はスレッドというべきものをプロセスと呼んでいたから。
内的な整合性が取れていればそれでもいいんだが、有用性でいうとあれ?って感じ。率直に言えば「使えない」。昨今のアカデミア軽視の風潮はこんなところから来ているのかもしれない。
スレッドと pthread
そういうわけで次はスレッド。
スレッドを生成した側のメインスレッドが先に終了して、同時にスレッドが意図しないタイミングで強制終了すると想定しない状況に陥るかもしれません。ここまでの例では、メイン関数側がスレッドの処理時間よりも十分に長い時間を待機させるようにしてそれを避けていましたが、メイン関数側は、生成したスレッドの終了するタイミングの長短にかかわらずスレッドの終了を待ち合わせるべきでしょう。
そーそー。しかし、わかりやすいですね。
そして提示されていたサンプルがこちら。
threadjoin.c
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
void *th_func(void *arg) {
puts("thread created");
sleep(10);
return NULL;
}
int main(int argc, char *argv[])
{
pthread_t th;
if (pthread_create(&th, NULL, th_func, NULL) == 0) {
puts("Main thread");
pthread_join(th, NULL);
puts("Main exit");
}
}
sleep に与える変数を変えると確かにその間もメインスレは待ってますね。
すげ。
セマフォ semaphore
pthread に相当する obj-c の機能はないかとあれこれ物色していたのだが、セマフォ semaphore がそれに該当するらしい。以下のサンプルを作成。
#import <Foundation/Foundation.h>
int main(int argc, const char * argv[]) {
dispatch_semaphore_t syncSemaphore = dispatch_semaphore_create(0);
// 非同期タスクの実行
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
// 何らかの処理
NSLog(@"非同期タスク実行中");
// タスクが終了したら、セマフォのカウンタを +1 にする
dispatch_semaphore_signal(syncSemaphore);
});
// セマフォのカウンタは当初 -1 なので、メインスレッドは停止している
dispatch_semaphore_wait(syncSemaphore, DISPATCH_TIME_FOREVER);
NSLog(@"非同期タスク終了");
return 0;
}
これ、セマフォがないと、メインスレッドの方が先に終了してしまい、必ずしも dispatch_async が処理されるとは限らない。
「非同期処理の同期をとる」のような時に使うらしい。
実行結果は期待どおり
非同期タスク実行中
非同期タスク終了
Program ended with exit code: 0
となる。
@synchronized とシングルトン
おまけ。この記事が参考になった。
参考:
『プロセス生成と実行』
『Linux スレッド pthread』
『MacOS/iOS スレッドプログラミング』
『Cocoa のマルチスレッドシステム』