

はじめに
以前に Save the DolphinS というプロジェクトをやっていた。
OpenDolphin という電子カルテは、データ構造に癖があり、カルテ記載内容の抽出ですら、それなりに難しい。
そのため Save the DolphinS では、データベースに直接アクセスしてデータの抽出を行うソフトの作成を行なっていた。ソフトは -味も素っ気もない言い方だが-「データ移行ツール」と呼んでいた。
「データ移行ツール」は dolphin データベースに直接アクセスして、一応
・カルテ記載内容全履歴→プレーンテキスト(画像などの特殊タグ付き)+画像など
・カルテ記載内容全履歴→ rtf 形式ファイル(画像などの特殊タグ付き)+画像など
に抽出するところまではできていた。(どういうものだったかは『電子カルテからの患者データの吸い出し』あたりを参照してください)

OpenDolphin 本体はおろかアプリケーションサーバである WildFly がなくてもデータベースさえ活きていれば、このソフト単体で動作してデータ抽出が行えるのでそれなりに重宝していた。
ただ、これだと、データを他のシステムに移行する場合には便利でも、たとえば保管はしておきたいが閲覧だけでいいという場合、視認性の面で今ひとつの感は拭えない。
何かうまい解決方法はないかなと思っていたのだが、ひょんなことから移行ツールの出力を html 形式で書きだせばいいことに気がついて、ソースコードを改変して試してみたところ、まずまずうまく動いた。
細かいところでさらに修正したいところはあるのだが、例えば、以下のカルテ画面(↓)
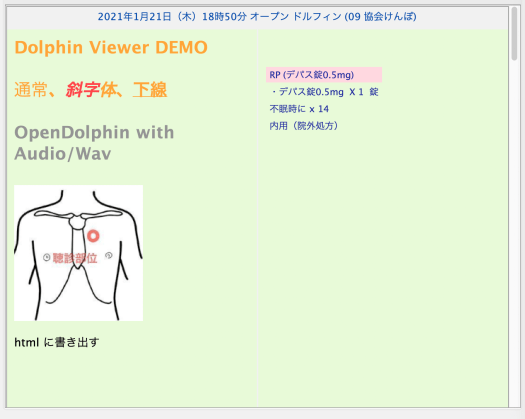
を、html 形式で書き出すとこんな感じになる。

2号用紙風のレイアウトやフォントの属性、画像の添付位置までほぼ完全に再現されていると思う。
データ抽出というコンセプトは同じでも、(移行を考慮して)データをテキストと画像などに分離させて出力するのと(閲覧性を重視して)それらをを html にまとめるのは、使用目的の点で微妙に異なる。
また、この機能を移行ツール内に同居させておくのは、ソースコード管理の面でも何かと不便だ。
そこで、この機能を分離させ、単独のソフトとして独立させることにした。
今後はこちらを
OpenDolphin Viewer
OpenDolphin HTML Viewer
OpenDolphin HTML/PDF Viewer (PDF 出力にも対応したため改名)
と呼ぶことにする。
開発グループを代表して
猪股弘明
背景色を変更
実務的にはまるで意味がないのだが、白背景は味気ない気がするので背景色を OpenDolphin 特有の薄い緑( dolphin’s green というのだそうだ)に変更。
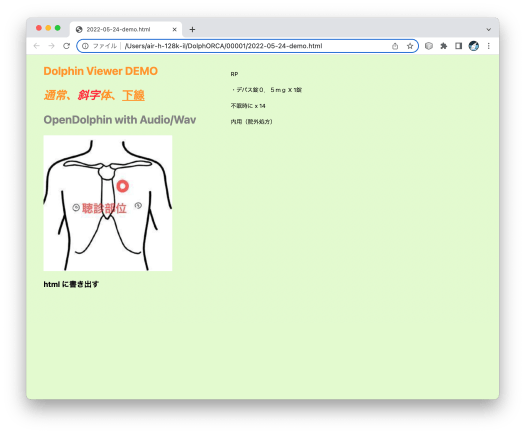
ドルフィン感が強くなった。
レスポンシブ対応
最近のウェブデザインは凝っていて、ブラウザの横幅を変更するとレイアウトを自動で調整してくれる。レスポンシブデザインなどというようだ。
この仕組みのおかげでPCのブラウザでもスマフォのブラウザでも、それなりに「見れる」レイアウトになっている。
これを狙って CSS を若干修正。
通常時がこうだとすると
ブラウザの横幅を縮小させるとある値(ブレークポイント)を境に右のいわゆる P 欄が左(SOA欄)の下に回り込む。

スマフォで閲覧することなどないかもしれないが。
P 欄(カルテ右半分)の検討
これまで、カルテの右半分(P 欄)は文字情報だけ抜いてきたが、実は処置・薬剤のレセ電コードも抜ける。
まだ、うまくまとめきれてないのだが、かなり雑にデータを書き出すとこんな具合になる。

赤枠で囲んだ部分が処置や薬剤の識別子(コード)で、その多くはレセ電コードと同一なはずだ。
実運用としては、ドルフィンから処置内容を ORCA に送った際に、この情報を受け取った ORCA はこれらコード番号に基づいて保険点数や窓口負担額を計算し、最終的にはレセプトに反映させている。
病院のシステムを入れ替えた際に、このコードが引き継げなくて処方内容を一から打ち込むことがよくある。とても負担だ。
本プロジェクトはデータの「閲覧」を強く意識しているが、上記の点に留意し P 欄に関しては若干レイアウトを崩してもこれらコードが表示できるようにしたいと考えている。
P 欄(カルテ右半分)の検討(続き)
通常 P 欄に記載される内容は、診断料や処方のほか各種検査のオーダーなどもある。
だから、まずドルフィン元カルテをこんな風にした。

カルテ左の SOA 領域よりも難しいのは、項目毎に処理を変えなくてはいけない点。
ここら辺、工夫してコードを修正。
現状だとこのようになっている。

プロトタイプとしては、十分な出来だろう。
なお、レセ電コードは、某所で聞いて見たところ「あったほうがいい」ということだったので、多少元カルテの表示と異なってくるが、表示させることにした。
また、この改変を機に元の OpenDolphin のコードは全て削ぎ落とした。
単純に表示させるだけなら、
dolphin データベース >> 読み込み >> オブジェクトの生成 >>
適当に修正して html 用に変換 >> 書き出し
とやった方が楽なのだが、P 欄に関してはレセ電コードを打ち出せるようには構成されていないので、結局、ここら辺のコードは全て廃棄した。
(SOA 欄は特殊タグを表示させる関係上、移行ツールの頃から使っていない)
html → PDF 変換
ところで、OpenDolphin の標準のカルテ画面の PDF 文書作成機能は、文字などもベクトルデータに変換していわば「画像」として PDF を生成しているようだ。
Mac の場合、フォントの関係(物理フォントと論理フォントというものがある)でデフォルトでは文字化けしてしまう。
そちらの修正はひとまずおいて、html → PDF 作成ができないか検討。
あれこれやっていたら、以下のように
 フォント埋め込み形式の PDF が生成できた。
フォント埋め込み形式の PDF が生成できた。
データ移行に関する厚労省の見解
実は、公式な文書はない。
ガイドラインの要請からして
・カルテ記載の文字情報や診断の根拠となったような画像の類
・処置内容の文字情報
・修正履歴や途中経過版
は最低でも移行しなければならないでしょう。
口頭でもそれっぽいことは言っていた。
現在、問い合わせ中です。→結局、明確な回答は得られず。
「最近、安全管理に関するガイドラインを公開したので、そちらを見ていただいて・・・」というような感じでお茶を濁そうとする。
「これだから、日本の医療 IT は」と思わないでもないが、文句を言っても始まらないので、ガイドラインに目を通す。
『医療情報システムの安全管理に関するガイドライン 5.2 版』というのがそれのようだ。
んー、しかし、これ、(例の半田病院の件を受けてだろうが)従来の電子カルテの3要件などの基本的要件に加えて、さらにシステムには医療記録のバックアップの仕組みを付け加えなさいよ、と言っているだけのような?
本当に知りたいのはバックアップ時に書き出す情報の種類や質といったことなのだが。
ただ、以前に比べれば、要求は具体的にはなってきた。
ポイントとなりそうなところを抜き出しておく。
1.バックアップサーバ
システムが停止した場合でも、バックアップサーバと汎用的なブラウザ等を用いて、日常診療に必要な最低限の診療録等を見読できるようにすること。2.見読性確保のための外部出力
システムが停止した場合でも、見読目的に該当する患者の一連の診療録等を汎用のブラウザ等で見読ができるように、見読性を確保した形式で外部ファイルへ出力できるようにすること。3.遠隔地のデータバックアップを使用した見読機能
大規模火災等の災害対策として、遠隔地に電子保存記録をバックアップするとともに、そのバックアップデータ等と汎用的なブラウザ等を用いて、日常診療に必要な最低限の診療録等を見読できるようにすること。(p. 61)
今回の HTML/PDF Viewer に絡めて言えば、このソフトを使って定期的にデータベースからバックアップを取っておけば、上記の条件を満たしているのは自明だろう。
「汎用のブラウザを使って」とあるが、html を表示できないブラウザはあり得ないので、お釣りがくるくらい(なにしろ画像や処方薬の薬剤コードまで表示してくれる)条件をクリアしている。
一応、バックアップは取っておいた方がいいとは思うが、データベースさえ生きていれば、サーバが停止してもこの条件は満たしている。
ところで、なんで厚労省の役人がお茶を濁そうとしたのかわかるような気もする。
商用の電子カルテでも上記の条件を満たしているシステムは(現時点では)そうは多くないからだ。
病院の電カル・HIS の場合、半田病院や大阪急性期総合医療センターの件で明るみに出されたが、ガイドラインで推奨されている基準でバックアップシステムを稼働している施設はほとんどない。
開業医さん向けの電カルは、この点はかなり改善されてきて、
・CLIUS
・owel
などは、この機能が公式に提供されている。
いわゆる商用の電子カルテとは一線をかくすが、
・ダイナミクス
・OpenDolphin-2.7m (系列。今回、説明したバージョン。他の派生物に関しては完全に把握しているわけではないが、おそらくない)
も、こういった機能が充実している。
サポート
HTML/PDF Viewer は、データベースのデータを直接参照するため、データベースの構造がわかっている場合には有効ですが、わかっていなければ、どう復号していいかわからず、復号ができません。
データベースを見れば、ある程度、類推はできますが、ソースコードがないと細かな依存関係は分かりません。
だから、2.3m (いわゆる増田ファクト)などは完全なサポートできません。
商用版の OpenDolphinPro ももうソースコードをユーザーに配布していないようなので、やはり復号が完全なものであるかは保証はできません。
たまに、何を勘違いしたか何の情報も持たずに「データ移行できませんか?」と問い合わせてくる人がいるので、注意喚起のために書いておきます。
どの程度復元できるかどうかは、あなたの持ち込んできた情報次第です。
また、『OpenDolphin-2.7m の「これから」』で「貸出」と書いていますが、われわれとて未知のデータを解析するにあたっては試行錯誤は必要です。
見ず知らずの第三者に貸し出すことはないでしょう。
常識的に考えてください。
(追記)OceanMini へのデータ移行は良いチャレンジになるので、取り組む予定です。



